#include <thread>
int sum = 0;
void Add()
{
for(int i = 0; i< 1000000; i++)
{
sum++;
}
}
void Sub()
{
for(int i = 0; i< 1000000; i++)
{
sum--;
}
}
int main()
{
//함수
Add();
Sub();
cout << sum << endl;
//스레드
thread t1(Add);
thread t2(Sub);
t1.join();
t2.join();
cout << sum << endl;
}100만번 값을 더하고 빼는 함수를 2가지 방법으로 실행했다.
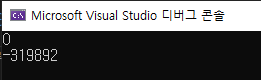
함수를 호출하여 실행할 경우 0이 된다는 사실은 너무나도 당연하다.
근데 스레드로 실행할 경우 sum은 항상 다른 값을 가진다.
공유데이터(힙 영역, 데이터 영역)를 다룰 때 이와 같은 문제가 발생할 수 있다.
여기서 sum은 전역 변수로 데이터 영역에 있어 두 스레드가 경합을 통해 접근하게 된다.
sum++ 또는 sum--의 경우 코드상에서 1줄로 보이지만 어셈블리어를 확인해보면 아래와 같다.

1줄이었던 코드가 컴파일이 되며 어셈블리어로 변환이 될 때 3줄이 되는 것을 볼 수 있다.
이 때 어떤 스레드가 sum++을 실행하기 위해 메모리에서 데이터를 가져오고 연산을 수행한 후 다시 메모리에 저장하기 전에 다른 스레드가 sum--을 수행하게 되면 연산을 수행하기 전의 데이터를 가져와서 처리를 하게 된다.
Add 스레드에서 0이라는 값을 가져와서 연산을 수행하려고 한다고 가정해보자.
동시에 Sub 스레드도 0을 가져와서 연산을 수행한다.
Add 스레드는 1이라는 값을 메모리에 저장했다.
Sub 스레드는 -1이라는 값을 메모리에 저장했다.
결과적으로 메모리에는 -1이 저장되었다.
위 과정의 순서는 언제든지 달라질 수 있기 때문에 1, 0모두 결과값이 될 수 있다.
sum++과 sum--가 모두 실행되었음에도 결과값은 항상 다르게 나올 수가 있는 것이다.
공유데이터는 굉장히 유용하지만 데이터를 수정하게 되면 위와 같은 문제가 생길 수 있다.
이를 원자성(Atomicity)을 만족하지 못했다고 하는데 원자성이란 완전히 실행되거나 실행되지 않거나 2가지의 상태만 가지는 것을 말한다.
이런 문제를 해결하기 위해서 아래와 같은 방법을 사용할 수 있다.
#include <thread>
#include <atomic>
atomic<int> sum = 0;
void Add()
{
for(int i = 0; i< 1000000; i++)
{
sum++;
}
}
void Sub()
{
for(int i = 0; i< 1000000; i++)
{
sum--;
}
}
int main()
{
//함수
Add();
Sub();
cout << sum << endl;
//스레드
thread t1(Add);
thread t2(Sub);
t1.join();
t2.join();
cout << sum << endl;
}atomic 헤더를 추가한 후 선언문을 atomic으로 묶어주기만 하면 된다.

정상적으로 잘 작동이 되는 것을 볼 수 있다.
그렇다면 모든 변수에 atomic을 사용하면 되는 것이 아닌가?
atomic은 연산이 꽤나 느리다. 또한 어떤 스레드에서 자원을 사용중일 경우 다른 스레드에서 해당 자원을 사용할 수 없기 때문에 병목현상이 생길 수 있다. 그렇기 때문에 반드시 필요할 때만 사용하는 것이 좋다.
'서버 > 멀티스레드' 카테고리의 다른 글
| 6. Sleep (0) | 2024.07.17 |
|---|---|
| 5. SpinLock (1) | 2024.07.14 |
| 4. DeadLock (0) | 2024.07.11 |
| 3. Lock (0) | 2024.07.11 |
| 1. 스레드 생성 (0) | 2024.07.10 |